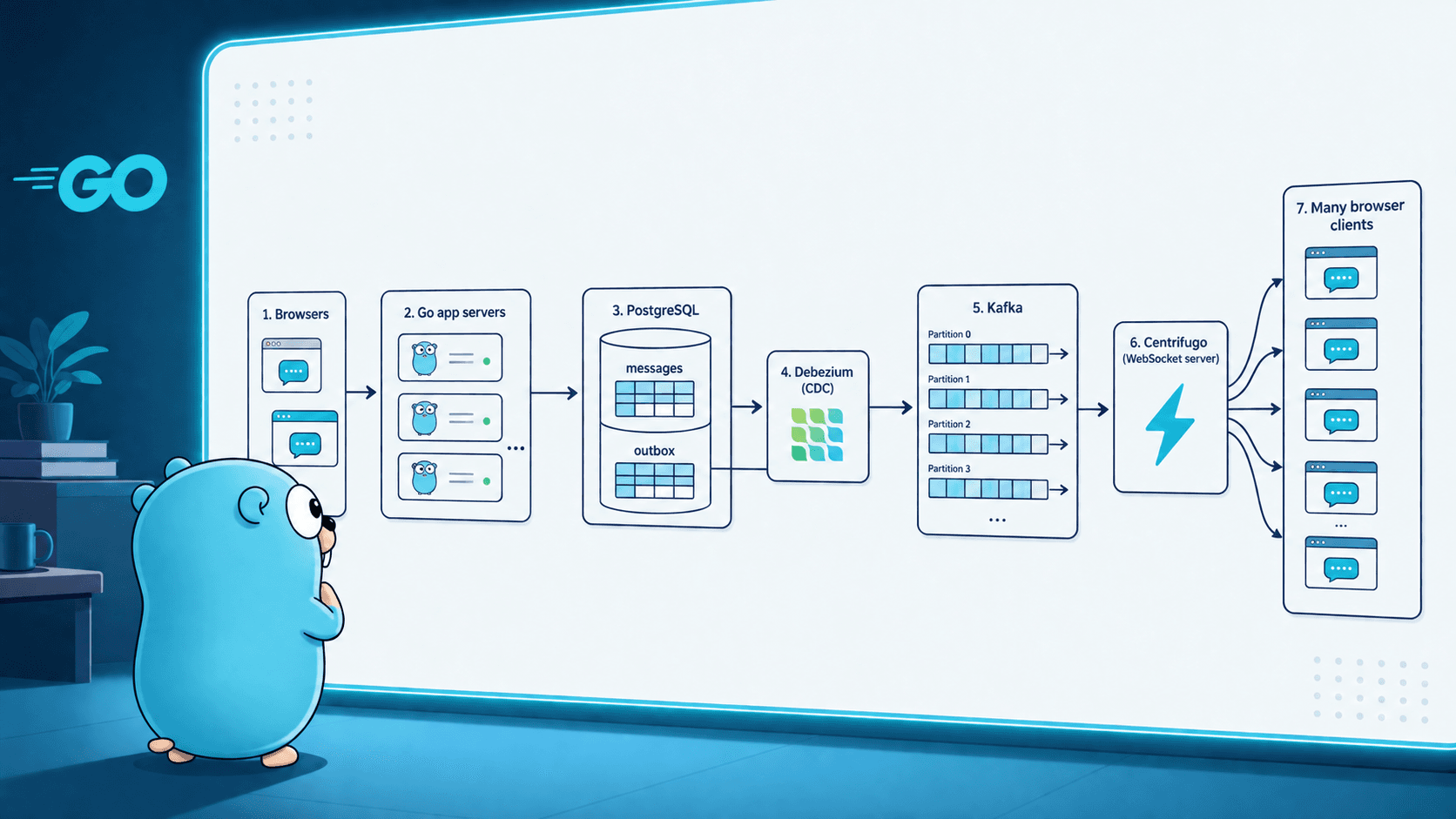
Design (and code) a job scheduling system

User story (simple)
As a user, I want to set up a time delay for my actions (e.g., send email) in a certain period, a certain day of the week, or a specific day of the year. So that my action can be executed with timing accuracy.
Function requirements
The requirement isn’t strict to any detailed use of the scheduling system. Then I map some concepts into an online marketing system, in which users need to set up a marketing campaign with steps of action running during a period.
[x] Ensure at least one delivery of every single job
- [x] Extra: prevent duplicate sends
[x] The scheduler should be horizontally scalable to handle ~5m timers at peak
[x] The user can change the value or cancel timers on the fly
[x] Fairness, priority some group of users
New signed-up users
Tenant with a small audience list.
The rest of the system, but shared the workload between them
[x] Monitoring metrics Monitoring system
[x] Time delay reports end-to-end processing time, from the time the job is due to the time it pulled out of the sending queue to process.
[x] Monitor the number of jobs processed per unit of time (e.g., per second)
[x] TPS: 5m new timers/hour, and 5m due timers/hour
[x] The scheduler should have a p95 scheduling deviation below 10 seconds
[x] Cost. The worker didn’t design for scaling another worker internally. I would defer it to a dedicated service like K8S HPA, or self self-managed service that reads the metric and schedules new worker instance
Scope
Backend Development: Focus on the backend, interacting with the system via APIs.
Scheduling System Implementation:
Design and implement a distributed job scheduling system without using/extending any existing Cloud or Open-source job scheduler.
Ensure the system can handle 10 million new and/or due timers per hour, with the potential to double this capacity.
Include a benchmark to demonstrate the system's capacity.
Exclusions:
- The implementation does not cover the actual job execution; the focus is on the scheduling aspect only. The jobs sent to the execution queue are done.
System design

Core components
API server: handle the user requests to schedule the job, handle the job delay time calculation
PostgreSQL database: central database, that takes the key role in data consistency.
Job processor: the due job checker, the heart of the system. Interval, concurrently check for the due job and send to queue
Due job fixer: as the nature of a distributed system the process may stuck due to network errors, or code bugs. The job fixer helps to ensure no job is left behind.
Data feeder: Feed the data to the system for demo purposes only
Monitoring service. Use an agent to collect metric data for monitoring from the service and workers
The ERD

Entities
I only describe the entities involved in the scope of this project
Tenant: to get the priority information
Sequence: The holder of the template for the jobs, including steps and subscribers
Step: The detailed information to build a job, could be a wait step or a job step
Subscriber: The subscriber subscribes to the sequence. In this scope, we simply refer to it as a number to count how many jobs we schedule for subscribers of sequence.
Job: The base unit of the scheduler system, the most important information is status and due time
For the simplicity of the demo, I only define the table for the Job entity
CREATE TABLE IF NOT EXISTS public.jobs
(
id serial
CONSTRAINT jobs_pk
PRIMARY KEY,
due_at timestamp DEFAULT NOW() NOT NULL,
priority integer DEFAULT 0,
tenant_id integer DEFAULT 1,
status integer DEFAULT 0,
metadata varchar(100)
);
ALTER TABLE public.jobs
OWNER TO postgres;
CREATE INDEX IF NOT EXISTS jobs_due_at_index
ON public.jobs (due_at);
CREATE INDEX IF NOT EXISTS jobs_priority_index
ON public.jobs (priority);
CREATE INDEX IF NOT EXISTS jobs_status_index
ON public.jobs (status);
Workflows
Users send a POST request to the API server and the system will auto-start the rest of the workflow. Below are the key workflows
- Schedule job process

Example request
POST <http://localhost:8081/schedule-job>
Content-Type: application/json
{
"type": "sequence",
"steps": [
{
"type": "wait_certain_period",
"delay_period": 1,
"delay_unit": "minute"
},
{
"type": "job",
"metadata": "{ 'any': 'thing' }"
},
{
"type": "wait_weekday",
"weekdays": [
"monday",
"tuesday",
"wednesday",
"thursday",
"friday"
]
},
{
"type": "job",
"metadata": "job 2"
},
{
"type": "wait_specific_date",
"date": "2023-12-29T18:48:34.200Z"
},
{
"type": "job",
"metadata": "job 3"
}
],
"subscribers": 20
}
To satisfy the design requirement. The schedule-job API accepts a sequence of steps, if the step is a wait step, we will calculate the relative due time, this due time will be the start of the next step in the step list.
No matter where the job step is in the step list, once we get into the calculation of the due time for the job, we only need to use the due time calculated by the previous step as the reference.
Refer to this unit test to understand the expected input and output
func TestCalculateNextJobs(t *testing.T) {
// Define a start time for the sequence
startedAt := time.Date(2023, 12, 28, 12, 0, 0, 0, time.UTC)
// Setup Sequence with steps
sequence := entity.Sequence{
Steps: []entity.Step{
&entity.StepWaitCertainPeriod{DelayPeriod: 1, DelayUnit: entity.DelayUnitMinute},
&entity.StepJob{Metadata: "{ 'any': 'thing' }"},
&entity.StepWaitWeekDay{WeekDays: []entity.WeekDay{entity.Monday, entity.Tuesday, entity.Wednesday, entity.Friday}},
&entity.StepJob{Metadata: "job 2"},
&entity.StepWaitSpecificDate{Date: "2023-12-29T18:48:34.200Z"},
&entity.StepJob{Metadata: "job 3"},
},
Subscribers: 2,
}
// Expected due dates for jobs
expectedDates := []time.Time{
startedAt.Add(1 * time.Minute), // 1 minute from startedAt (Job 1)
time.Date(2023, 12, 29, 12, 1, 0, 0, time.UTC), // Next weekday (Friday) for Job 2
time.Date(2023, 12, 29, 18, 48, 34, 200000000, time.UTC), // Specific date for Job 3
}
got, err := controllers.CalculateNextJobs(sequence, startedAt)
if err != nil {
t.Fatalf("CalculateNextJobs() error = %v", err)
}
if len(got) != len(expectedDates) {
t.Fatalf("Expected %d jobs, got %d", len(expectedDates), len(got))
}
for i, job := range got {
log.Print(i, job)
if !job.DueAt.Equal(expectedDates[i]) {
t.Errorf("Job %d due at %v, want %v", i, job.DueAt, expectedDates[i])
}
}
}
After the job calculation, it will be sent to the database for the bulk insert.
- Due job checker

After the jobs are inserted into the database with the due date, the due-job-checker workers can pull it from the database.
I use Postgres advisory lock here to ensure only one worker can pull the job at the same time.
But I still use the SELECT FOR UPDATE here to ensure no other process updates my records while I select it.
rows, err := conn.Query(`
UPDATE jobs
SET status = $1
WHERE id IN (
SELECT id FROM jobs
WHERE due_at <= NOW() AND status = $2
ORDER BY priority
LIMIT $3
FOR UPDATE SKIP LOCKED
)
RETURNING id, due_at`, entity.JobStatusInProgress, entity.JobStatusInitialized, dueJobBatchSize)
The lock is released early right after I update its status to processing, this will help to increase the throughput of the system while other incoming actions don’t rely on the database.
- Due job fixer

To keep the queue table tidy. We need to clean up it frequently. This worker will internally (15 seconds) archive the processed job, in a real system I would move it to the archived table, but in this demo I simply just delete it.
For some reason, if the job fails to process after the maximum processing time limit (let’s say 10s), it is considered a failed job and moved back to the queue.
It is out of scope so I don’t go further on this but in a real system, we need to check more criteria to decide if a job has failed and retry it, not just the exceeded processing time criteria.
Monitoring system
I use external tools for monitoring. Prometheus to collect the metrics and Grafana to plot the data. The tools defined in the docker-compose.yml file

The general idea is to use the Prometheus SDK to collect the metric and send it to the Prometheus push gateway. Then set the Grafana to select the data source.
The metrics I collect
Job process TPS. This is the number of jobs this system can process per second. As you can see in the screenshot below, the TPS average is ~20.000 jobs/second.
According to the requirement of 5M new timers + 5M due timers = 10M jobs/hours.
It can be doubled at any time = 20M jobs/hours
So 20.000 jobs/sec 60 60 = 72.000.000 jobs/hour. This design can cover the system requirement more than 3 times.
Note that this system runs on my local machine (MacBook M2 pro base edition), the Postgre database runs in docker with some resource constraints so the real system on the cloud can be much more capable of the higher load.

The p95 of the job due time delay
An average of 95% of job processing time is 1148 ms. Calculate from the exact UTC that the job due, to the time it is marked as processed.
This metric is the delayed time from the time the user expected it to be sent to the time it is sent.

Job in queue
In my data feed, I set it up to schedule a job now and another job delayed 1 min later. As you can see the system is processing both new timers and due timers. As the data feed keeps running every second, this chart won’t be low unless I stop the data feed. But we can expect every job will be processed in about 1 second.

Design decision
Why Go
I need the robustness of the language and its ecosystem
Foolproof, not afraid of making code mistakes, many good practices and standards can be found online
Concurrency model.
Why PostgreSQL
Mostly a silver bullet for most projects that need robustness and flexibility. For example
I utilized advisory lock,
select for updateskip locked for this projectIn another project, I utilize the
jsonbquery and view.
Rich documentation and resources
Extending ideas
If I have more time on this project I will refactor it following the Clean Architecture structure to avoid logic fragmenting in many services workers. But for the scope of this project, the structured method works fine.
Add more integration tests and load tests for all the critical functions. I already have some tests but it is not enough to ensure the robustness of this system. Especially in the concurrent environment.
Read me
Repository
https://github.com/finnng/job-scheduling-system
Prerequisites
Go version 1.21.0
docker-compose (you may need to update docker-compose.yml for intel based computer)
Steps
Pull the source code
Start the databases:
docker compose up -dCreate a Postgre test database. Use any database client to create a database name
testand grant permission for the default userpostgreon it.
CREATE DATABASE test;
GRANT ALL PRIVILEGES ON DATABASE test TO postgre;
- Start the API server, it should automatically provision the tables. From the repo’s root directory, type
go run api-server/app.go
- Start other workers to complete the full system, open other terminal tabs for these commands
go run worker-due-job-checker/app.go
go run worker-job-fixer/app.go
go run data-feed/app.go
The data-feed worker will randomize the test data and send it to the API server to keep the system busy for the demo purpose. You can edit the test request to test all the cases of the scheduling scenario.
payload := Payload{
Type: "sequence",
Steps: []Step{
{
Type: "job",
Metadata: "{ 'any': 'thing 1' }",
},
{
Type: "wait_certain_period",
DelayPeriod: 1,
DelayUnit: "minute",
},
{
Type: "job",
Metadata: "{ 'any': 'thing 2' }",
},
},
Subscribers: rand.Intn(10000) + 1, // Random number between 1 and 1000
}
Your terminal panels should look like this.

Monitoring
I haven’t handled the Grafana database migration yet, so you need to head to the Grafana dashboard at http://localhost:3000 according to the docker-compose file Grafana port.
Setup Prometheus as the data source
Play around with the metrics sent from the scheduling system

The complete dashboard should look like