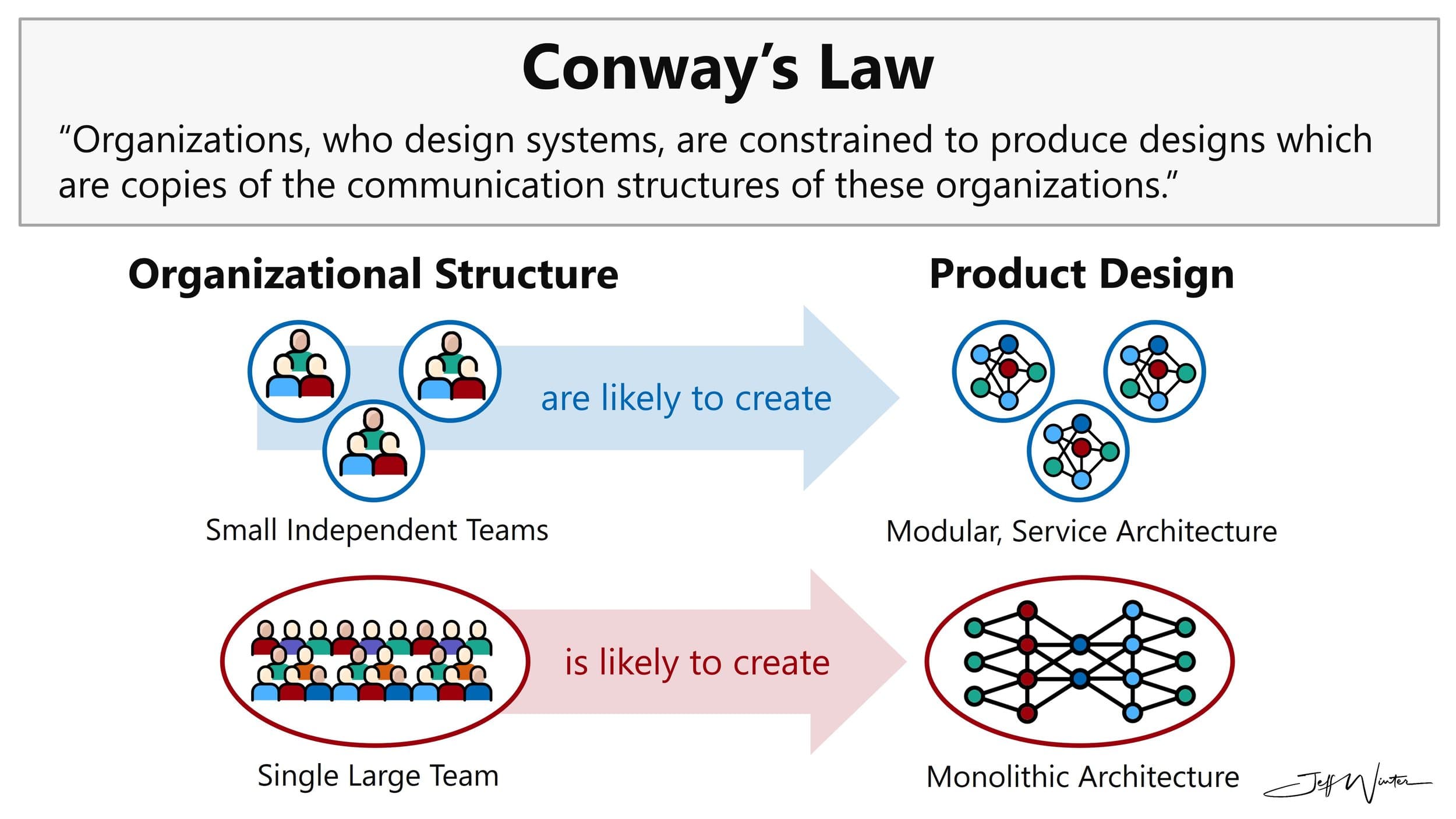
Building a data analytic Slack App with Machine Learning
Discover How to Make a Smart Slack App with ML, Cloud Runs, and Golang/Python.

As developers, we've all been there – drowning in a sea of Slack alerts, desperately trying to spot the critical issues amidst the noise. It's a common problem, but what if we could use machine learning to make sense of this chaos? That's exactly what I set out to do, and I'm excited to share my journey with you, including the intricate details of how I built and deployed this solution using modern cloud architecture.
The Challenge
Picture this: You're working on a complex system, and your Slack channel is constantly bombarded with alerts. Some are critical, some are noise, and distinguishing between them becomes a time-consuming task. This was my reality, and I knew there had to be a better way.
The Solution: Unsupervised Machine Learning and Cloud Architecture
I decided to tackle this problem head-on by applying unsupervised machine learning to cluster Slack messages and identify error patterns. But the solution went beyond just the ML algorithms – it involved creating a robust Slack app and leveraging cloud services for seamless deployment and scalability. Here's why I chose this approach:
Learn by doing: There's no better way to understand machine learning and cloud architecture than by applying them to a real-world problem.
Slack app development: This project allowed me to create a non-workflow Slack app, a valuable skill for future needs.
Cloud services practice: Implementing this solution gave me hands-on experience with Google Cloud Platform services.
Real-life ML application: It's one thing to understand ML theoretically, but applying it in a production environment is a whole different ball game.
CI/CD implementation: Setting up continuous integration and deployment for the Slack app provided practical experience with modern DevOps practices.
More Golang practice: As an added bonus, I got to code in Go, which is always fun!
The Technical Deep Dive
Now, let's get into the nitty-gritty of how this system works, from the ML algorithms to the cloud architecture.
Machine Learning Pipeline
Preprocessing the Text
Convert all text to lowercase
Remove punctuation
Split the text into individual tokens (words)
Remove common "stop words" that don't add much meaning
Apply stemming to reduce words to their root form
Vectorizing with TF-IDF We use the Term Frequency-Inverse Document Frequency (TF-IDF) algorithm to convert our preprocessed text into numerical vectors.
Clustering with DBSCAN With our text converted to vectors, we apply the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm to group similar messages.
Slack App Pipeline
The Slack app pipeline is where the magic happens. Here's how it works:

A user interacts with the Alligator Slack app, initiating the process.
The app sends a request to our Google Cloud Run service.
The service responses with the Blockit schema that define the Slack modal.
The app presents a modal to the user, allowing them to select a time range for analysis.
Once the user submits the time range, another request is sent to the Cloud Run service.
The service send a link to a report to Slack app. This time the report is not ready yet, users will need to wait a little bit.
The background work in the service processes the messages within the specified time range using our ML pipeline, which includes downloading and processing the relevant Slack messages.
Finally, the app displays the clustering results to the user in a neatly formatted message.
This pipeline allows for seamless interaction between the user, the Slack interface, and our backend ML processing.
Result

Google Cloud Platform Architecture
To ensure scalability, reliability, and ease of deployment, I leveraged several GCP services:

Cloud Source Repositories: This is where our code lives. It's directly integrated with other GCP services, making our CI/CD pipeline smooth.
Cloud Build: Whenever a commit is pushed to the master branch, Cloud Build automatically triggers a new build.
Artifact Registry: My built Docker images are stored here, ready for deployment.
Cloud Run: This is where our application runs. Cloud Run automatically deploys new versions of our app whenever a new image is pushed to the Container Registry.
The workflow looks like this:
I make changes and commit to the master branch in Cloud Source Repositories.
This triggers Cloud Build, which builds a new Docker image.
The new image is pushed to Container Registry.
Cloud Run detects the new image and automatically deploys it.
This setup ensures that our Slack app is always running the latest version of our code, with zero downtime during updates.
Lessons Learned
This project taught me a ton, and I want to share some key takeaways:
LLMs aren't everything: Sure, Large Language Models are cool, but traditional ML techniques still have their place. Don't forget about them!
Fundamentals matter: Understanding and applying basic ML techniques is super valuable. It gives you the flexibility to solve unique problems.
Cloud architecture is key: A great algorithm is only as good as its deployment. Cloud services give you the scalability and reliability you need for real-world applications.
CI/CD streamlines development: Setting up a good CI/CD pipeline makes development and deployment so much smoother. It's worth the effort!
Humans in the loop: Even with all this automation, ML and AI apps still need human oversight and tweaking.
Use the right tool for the job: While Go is awesome, it's not always the best choice for every task, especially when it comes to machine learning.
The Go vs. Python Saga
Here's a funny story - after I built the whole thing in Go, I realized it wasn't the best fit for the ML parts. Don't get me wrong, I love Go, but sometimes you gotta know when to switch gears.
Initially, I implemented both TF-IDF and DBSCAN in Go. It worked, but man, was it slow! Processing 4MB of data with about 2000 feature dimension vectors took a whopping 9 minutes. That's when I knew I had to rethink my approach.
The problem wasn't Go itself, but the lack of a mature ML ecosystem around it. I couldn't find optimized implementations of the data structures and math formulas I needed, which are readily available in languages like Python.
The Hybrid Solution
So, I came up with a hybrid approach:
Keep the main app structure in Go, because it's great for building efficient, concurrent systems.
Switch to Python for the core ML algorithms (TF-IDF and DBSCAN), taking advantage of its rich ecosystem of ML libraries.
Use Go to wrap around the Python script, calling it when needed for the ML tasks.
The results? Mind-blowing. The same dataset that took 9 minutes in pure Go now took just a few seconds in Python. Talk about a performance boost!
Key Takeaway
This experience really drove home a crucial point: use the right tool for the right job. It's tempting to stick with one language or tech stack, but sometimes the best solution involves mixing and matching.
In the world of ML and data processing, the ecosystem around a language can be just as important as the language itself. Python's extensive ML libraries make it a powerhouse for these tasks, even if we might prefer other languages for different parts of the app.
Keeping Our Secret Sauce
Now, let's talk about LLMs for a second. They're all the rage right now, and for good reason - they're pretty amazing. But here's the thing: they're not the answer to everything. By using fundamental algorithms to solve our problem without sending data to OpenAI or similar services, we're keeping our core competencies in-house.
Why is this important? A few reasons:
We keep our data private and secure.
We can customize our algorithms exactly how we want.
We can optimize performance for our specific needs.
For high-volume stuff, it might even be cheaper than using API-based services.
By developing and maintaining these core capabilities ourselves, we're making sure that our critical know-how stays, well, ours.
What's Next?
As with any project, there's always room for improvement. Some next steps include:
Optimizing for larger datasets
Integrating LLM-based summarization of errors
Improving the app's distribution and installation process
Adding more robust monitoring tools
Exploring other cloud services to further enhance scalability and performance
Remember, while it's great to leverage cutting-edge tools and services, don't outsource your core competencies. This project wasn't just about solving a problem - it was about expanding our skills in crucial areas of modern software development. From ML to cloud architecture to DevOps practices, we've grown a lot. And perhaps most importantly, we've learned when to adapt our approach and use different tools to get the best results.
Have you faced similar challenges in your projects? How do you decide when to use external services versus building in-house capabilities? Drop your thoughts in the comments - I'd love to hear about your experiences!