Migrating a decade of production data from an abandoned database (RethinkDB) to MongoDB
The tool and process we built to move a TB of live data without downtime and without blocking the team

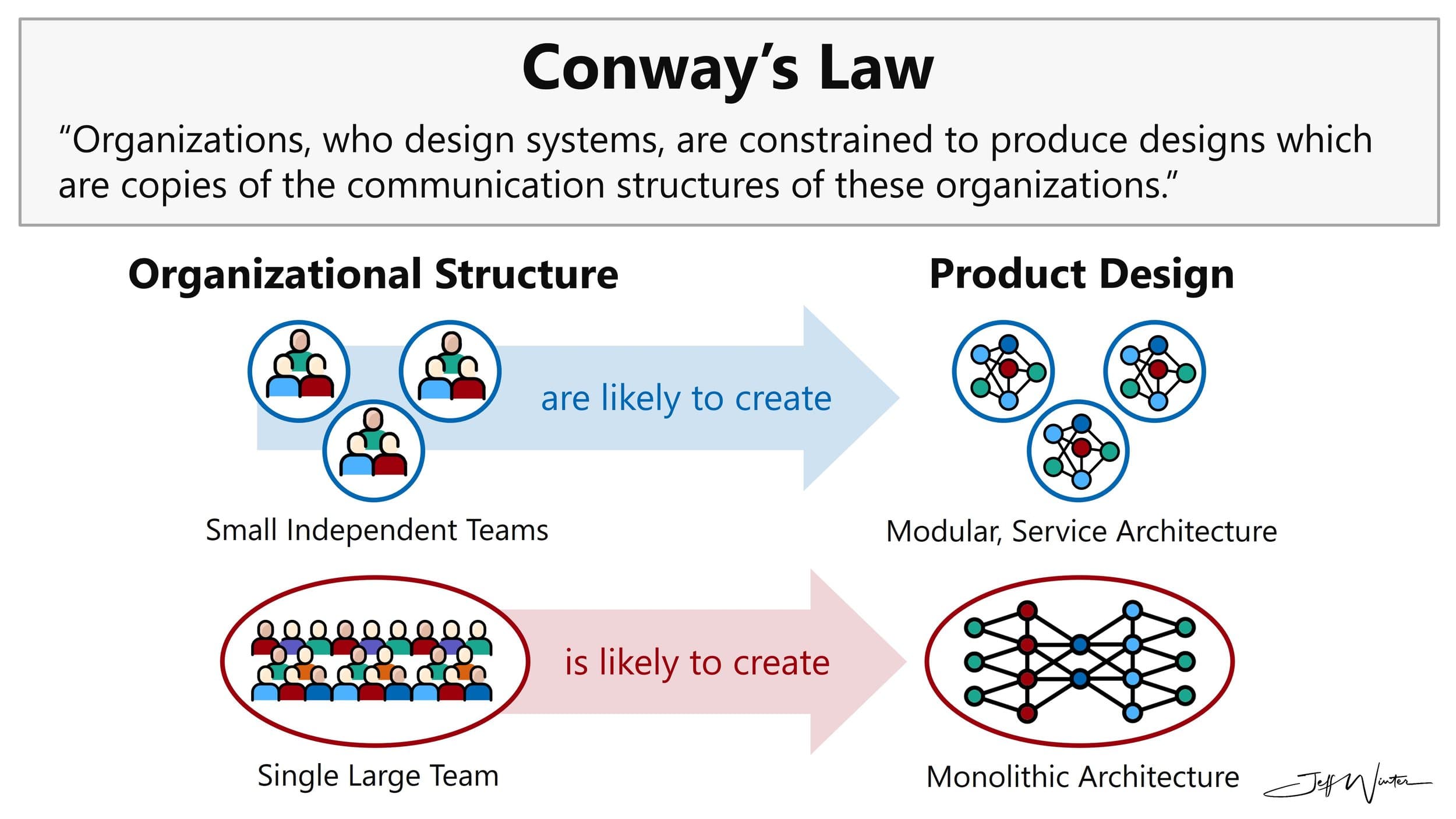
Back in 2015, when the Node.js, NoSQL, and microservices ecosystem was still fresh and the tooling hadn’t matured, choosing one solution over the other would be a hit-and-miss situation. We didn’t know if the technologies we chose would live along with the product we built on them. Luckily, some of the choices were right, like we chose React over AngularJS. Google quickly abandoned AngularJS 1.0’s architecture, and the version 2.0 is a totally different architecture. But we weren’t lucky in choosing RethinkDB over MongoDB. In 2015, they were still competitors, and RethinkDB was better for several reasons:
Realtime by default: RethinkDB gave you native changefeeds, so apps could subscribe to live query updates instead of building polling or oplog-tail logic around MongoDB.
Better fit for live apps: It was designed for dashboards, collaborative tools, multiplayer systems, and other “realtime web” use cases where MongoDB was more of a general document store.
ReQL was more elegant: RethinkDB’s query language was chainable and embedded in your host language, so it felt cleaner than assembling MongoDB-style query documents and driver calls.
More powerful querying: RethinkDB emphasized joins, subqueries, and aggregations in the database, which made complex document queries easier than MongoDB’s then-limited relational story.
Simpler clustering: Sharding and replication were presented as easy to set up, with a web admin UI that reduced operational friction.
Stronger consistency story: RethinkDB marketed itself as “a MongoDB done right,” stressing MVCC, non-blocking writes, durability by default, and better correctness trade-offs.
More attractive developer experience: Reviews from the time repeatedly called out ease of use, clear docs, and “just works” realtime behavior as reasons people got excited about it.
MongoDB needed extra plumbing: If you wanted similar realtime behavior in MongoDB, you usually had to add another layer yourself, which is why RethinkDB felt more complete for that niche.
Internally, the product team also aimed to build a real-time web app. We chose React to build the SPA frontend. And as the team said, the backend also using a real-time database “makes perfect sense".
Then on a rainy day out of the blue, RethinkDB company announced that they will shut down https://rethinkdb.com/blog/rethinkdb-shutdown/. No more new features or bug fixes. They left us with one of the biggest technical debts. Migrating away from it is obvious, but one of the company's most competent features is built on top of it. The company is also a startup, so releasing new features to get to the top of the market is the most important thing. And the plan to migrate from it was delayed for years, until the day the product is mature, and the coming of AI makes it feasible.
In this post I’ll walk through why none of the obvious migration approaches fell apart under our constraints, how we designed a Data API to hide the migration from the rest of the team, and how a purpose-built Go migrator with distributed locks and time-windowed checkpoints moved terabytes of live data with only minutes of downtime.
Problem statements
Migrate away from RethinkDB to MongoDB is one of our multi-year plans to modernize the system. With over TB of data, 200+ tables, and the 99.9% downtime requirement, we need a solid migration process and tool that can tolerate errors and run the migration simultaneously on several tables, while maintaining data consistency.
RethinkDB is no longer maintained, so the modern approach like using the CDC doesn’t exist. The nearest thing to CDC is the native RethinkDB change feeds, which is unreliable because the change feeds only work if the consumer is live. If the network blips or the migrator is restarted, then we lose the data changes.
As we migrate data, we still need to serve the production traffic, an event-driven system serving 30M+ events per day, we can only put the system to maintenance mode for like 10 minutes during the night.
Some of the proposed solutions are:
Dump the data from RethinkDB then import to MongoDB: This doesn't work because the dump requires a long downtime, and the dumping tools for RethinkDB are also slow and unmaintained, the MongoDB import tool is also slow on hundreds of GBs of data, and if there are failures we need to start from the beginning.
Stream the data directly: this also doesn't work because it can't guarantee the data consistency on live system. Stream data is a point-in-time cursor scan, any document inserted, updated, or deleted after the cursor has already passed it will be silently missed.
Use RethinkDB change feeds: As I mention above, it is unreliable and the event doesn't guarantee to delivery at least once, if the connection drops, all events that occurred during the gap are permanently lost with no built-in offset or replay mechanism to resume from.
The 10+ years code base is also a challenge when the RethinkDB queries embedded into both the test and code files across 3 languages Nodejs, Go, and C# within million lines of code.
And most importantly, we are not only migrating data in a live production system, we also migrate the code where the rest of the team is still pushing the product feature every day. We can't just block the deployment until we finish the code; we need to merge the code gradually and give the team the room to hot fix their product feature issue if any.
I will break down the problems and solutions, considering the trade-offs involved. Every problem has sub-problems, and so do the solutions. We have made several important decisions, and I hope to have enough time and space to present them all. However, if anything is unclear, feel free to leave a comment. I will reply to it or update the post to address it.
The general solution

The key requirement is how to migrate the data while the team still work on the same code base, build feature that requires database query while the migration code and data change keep moving spontaneously
We considered two approaches
- Approach A: Direct query replacement behind a
migrationStatusflag
// Run a database operation depending on current migration status
procedure runQuery(oldDbOperation, newDbOperation):
if migrationStatus is NOT_STARTED:
// operate only on old database
result = execute oldDbOperation
return result
else if migrationStatus is MIGRATING:
// operate on both databases, in parallel
resultFromOld = execute oldDbOperation
execute newDbOperation
wait until both operations are finished
// use old database result as the source of truth during migration
return resultFromOld
else if migrationStatus is MIGRATED:
// operate only on new database
result = execute newDbOperation
return result
else:
// invalid state
signal error "Invalid migration status"
- Approach B: Data API over HTTP, like the Supabase API, where all database access goes through a shared HTTP service instead of a direct SDK. So instead of a query like
SELECT name FROM users WHERE userId = x, callers just callawait readDocumentById('users', id, ['name'])
In the scope of this post, I will only introduce the Data API pattern but not dig deep into it, it is a sophisticated service and worth a separate post to cover the details. What is relevant here is that each table has a migrationStatus field in the migrator's tracking document, and the Data API reads it on every request to decide which database to talk to. During Migrating, every write goes to both databases and reads come from RethinkDB. Once an operator marks a table Migrated, the Data API drops RethinkDB entirely for that table and routes all traffic to MongoDB — with no deployment and no code change required.
We chose the Data API approach after considered several trade offs
Accessibility over the performance. Other team also need to access the same database, if we choose (1), the other team need to write the new query and the migration themselves. The Data API will expose as the HTTP server so other team can just call the Data API without knowing which database serving the request.
- We also need the Data API to auto-scale based on workload. Ideally, we will keep it inside a Kubernetes cluster, but Cloud Run offers the same horizontal and vertical scaling ability and the ease of access to other team members. Then, we choose Cloud Run for deployment.
Fast execution over performance. If we use the migrator in approach (1), we need to replicate this across 3 implementations in Node.js, C#, and Go, not to mention the direct RethinkDB query in the test files across 3 languages. By replacing it all by HTTP calls with the unified interface, we hide all the migration behind. The team can continue to work on the feature without knowing the migration behind the Data API call. If we just replace old queries by the new queries, it costs us the same effort and slows down the execution as the team still works on the same codebase; conflict is inevitable.
The system is mature, so we need to design the solution based on the existing infrastructure and design rules:
The services and workers running inside the Kubernetes cluster for auto-scaling.
The workers can't access the database directly; only the service can call the database to prevent the exhausted connection pool by having too many worker instances.
The database is outside of the Kubernetes cluster to provide easy access to other teams as we shared the database. Ideally, each team will own their database, but in practice, to save costs, we usually use the same database instance.
The database migration tool
Here is the main part that keeps the migration process safe and fast. But first, let's review the requirements again so I can explain the design decisions to satisfy them.
TB of data is live on production while all the migrations run in the background. We can only tolerate a few minutes down at midnight.
Data integrity is non-negotiable; rollback is hard because the live data keeps writing to the database.
Avoid the operational risk of human mistakes.
The timeline is tight; we need to migrate tables in parallel to speed it up.
We need some data manipulation before inserting data from RethinkDB to MongoDB because the two systems handle absent values differently. RethinkDB stores explicit
nullfields inside documents, while MongoDB applications typically treat a missing field and null as distinct things. Keeping those null fields would silently change query behavior, so the migrator recursively strips all null values from every document — including nested objects and arrays — before writing to MongoDB.The process should be resilient, tolerant of network issues, server crashes, and running inside Kubernetes to reuse the existing infrastructure and vertically auto-scale.
I came up with the design, in general.
The migration tool is a single Go service: a web dashboard to control migrations and a background worker engine. One binary, deployed in Kubernetes.

Why Go
The migrator needs to run up to at least 20 concurrent workers, sustain steady memory pressure for days at a time, and stay maintainable by a single engineer who may not touch it for months. Node.js was ruled out early — it's hard to hold a long-running process steady under high heap load, and its event loop model makes true parallelism awkward when you need goroutine-per-worker isolation with clean, explicit cancellation. Go's goroutines and sync primitives gave us that naturally, and the context package made cancellation and timeout propagation explicit all the way down the call stack — critical when a crashing pod must release a distributed lock cleanly.
Static typing also mattered. A migration tool is not product code; no one is going to refactor it frequently, and the person who picks it up next might not have full context. Go's compiler catches whole classes of mistakes before they reach production, and Go's compatibility guarantee means the binary compiled today will still build and run on a future toolchain without surprises — no npm audit roulette, no breaking major version upgrades to chase.
Building this tool also sharpened my Go fundamentals in ways I hadn't expected: designing worker pools that are free of race conditions, using sync, context, and log/slog idiomatically instead of pulling in frameworks, and keeping the dependency count low so the tool can outlast the migration itself without rotting.
The dashboard was a deliberate choice too. Instead of a React frontend, a separate API, and a build pipeline to maintain, I used Go's html/template package and wired interactions with htmx. Every action — start, stop, reset, reclaim a lock — is a single HTML attribute and one server endpoint. No JavaScript, no bundler, no frontend dependencies to audit. Combined with Go's embed package for static files and the table config CSV, the entire service — migrator engine, scheduler, and dashboard — ships as one binary. Deploying an update in Kubernetes is rolling out one image.
The table list is an embedded CSV in the binary — table names, collection names, connection strings. On startup the service seeds a tracking document per table into MongoDB. This is the source of truth: migration phase, progress, and lock state for each table. It also computes a safe batch size per table from RethinkDB stats (100MB ÷ avgDocSize) to keep memory usage bounded.
Scheduling and distributed lock
Every 30 seconds, BootstrapWorker loads all Migrating tables, sorts by who ran least recently, and fills up to 20 worker slots. When it wants to start a worker, it does one atomic FindOneAndUpdate in MongoDB to claim the lock. If another pod holds a valid lock, it skips that table. Locks have a 3-minute TTL with a 1-minute heartbeat — if a pod crashes, the lock expires and another pod picks it up.
BootstrapWorker (every 30s)
├── worker already running? ──YES──► skip
├── 20 slots full? ──YES──► wait next tick
├── lock acquired? ──NO───► skip (other pod)
└──► Start Worker
Workers run one cycle then exit, freeing their slot. The 30-second tick is the loop — this is what lets the scheduler fairly rotate across all 150 tables instead of 20 workers running forever and starving the rest.
What one worker cycle does

The write hook in step 1 is the backbone of the whole sync: RethinkDB automatically stamps __lastModifiedAt on every insert or update, which is what lets the data sync query only what changed since the last cycle.
Each worker runs three steps in sequence. First, it verifies the __lastModifiedAt index exists on the RethinkDB table and creates it if missing. Then it processes any pending deletions that the Data API has already recorded in MongoDB. Finally, it runs a Between range scan on the __lastModifiedAt index for the bounded time window, reads documents in batches, strips null fields from each one, and bulk-upserts them into MongoDB using ReplaceOne with upsert: true, keyed on the table's RethinkDB primary key. The lastBackfillAt checkpoint is written to the tracking document only after the full time window commits successfully — so a crash means at most one 15-minute window is re-processed on the next cycle, not the entire table.
For data sync, the time window advances each cycle with a small backward overlap to handle clock skew and data replication lag, and a 15-minute forward cap so a large backlog gets drained incrementally rather than in one huge scan.
──────────────────────────────────► time
[ previous cycle ][─5min][ this cycle ≤15min ]
▲ ▲
fromDate toDate
(lastBackfillAt moves here)
Here is a few of the most asked questions about this tool
Q: Old documents in RethinkDB never had __lastModifiedAt — how does the first sync pick them up?
A: The index creation defaults missing __lastModifiedAt to now at index build time, grouping all old docs under the same timestamp. The first run also has no cap — it scans from the beginning of time to now, so everything gets swept in one pass.
Q: Who writes the deletion tracking records — the migrator?
A: No. The Node.js Data API writes a tracking record into MongoDB before and after every delete from RethinkDB. The migrator only reads that collection. It never observes RethinkDB deletes directly.
Q: What if the migrator crashes mid-table?
A: The lock expires in ≤3 minutes. The next BootstrapWorker tick on any surviving pod claims it and resumes from lastBackfillAt — the last committed checkpoint. At most 15 minutes of work is repeated due to the cycle cap.
Q: What if a document is updated in RethinkDB while the migrator is currently processing that same window?
A: The write hook updates its __lastModifiedAt to now, pushing it past toDate. The next cycle's window picks it up. The 5-minute backward overlap also acts as a safety buffer.
Q: How do you know when a table is fully migrated and safe to cut over?
A: The dashboard shows migratedDocCount vs totalRethinkDocs. When they converge and deletions are drained, the table is a candidate for cutover. The actual switch happens at midnight: we put the system in maintenance mode for a few minutes, deploy the feature flag values that tell the Data API to read from MongoDB for the target tables, and during those minutes the data is identical in both databases so there is no risk window. Then we click Complete in the dashboard to stop the migration workers for those tables and bring production back up. After that we run regression and smoke tests on prod to confirm. We also have a rollback plan if anything looks wrong, but that deserves its own post.
Q: 20 parallel workers still means 20 simultaneous reads on RethinkDB — is that fine?
A: Each worker reads at most ~100MB per batch, not the full table. The 20-slot cap was tuned to the cluster's comfortable read concurrency. It's light, sustained pressure rather than a spike. And we can always increase this limit.
Q: How do you verify the migrated data is identical between RethinkDB and MongoDB?
A: We built a separate validation worker. After every successful read through the Data API, the service asynchronously publishes a verification message to a Pub/Sub topic — fire-and-forget, so it never adds latency to the actual request. A 10-minute deduplication window prevents the same read from flooding the queue.
The worker picks up the message, replays the identical request against both the RethinkDB and MongoDB endpoints concurrently, then normalizes both responses: stripping database metadata fields (_id, __lastModifiedAt), removing nulls, and sorting keys alphabetically for a stable comparison. Then it runs a deep equality check. On any mismatch it generates a detailed diff and logs it.
This only runs on tables still in the Migrating phase, so real production traffic continuously validates the migration without any overhead on already-completed tables.
Results
So far, 100+ tables and over a TB of data have been fully migrated without incident. That doesn't mean the path was smooth — we hit OOM panics in the early weeks and found some bugs along the way. Both were addressed: OOM by tightening the batch size calculation, bugs by patching the worker logic. The service has 95% test coverage across unit and integration tests, and we ran it on staging for months before touching production, so most of the hard surprises were already behind us by the time real data was involved.
Throughput isn't our bottleneck — the migration runs in parallel with the team rewriting direct RethinkDB queries to Data API calls, so we don't rush it. That said, the tool can move roughly a TB within a single working day when given the bandwidth. And because the pull-and-lock model is stateless, scaling is just adding pods — no coordination required.
Observability is deliberately simple: per-table progress on the dashboard, worker errors logged directly into the tracking document, and Kubernetes resource metrics for the rest. We haven't wired up external alerting yet — it wasn't worth the integration cost for an internal tool at this stage — and the dashboard has been enough to catch issues in practice.
Final thoughts
One thing that isn’t obvious from the architecture: before this tool existed, migrating a table meant running bash scripts manually — on a dev machine, a VM, or a Cloud Run instance — each one adjusted by hand per table. Miss a step or run them out of order and the table ends up in an unknown state with no easy recovery. With 200+ tables in the pipeline, that was a real operational risk, not a hypothetical.
The tool replaced all of that with a few clicks on a dashboard. What used to take hours or a full day for a single table now takes minutes. And the company stopped carrying a category of risk it didn’t even know it had.
In the end, this migration wasn’t about some clever trick. It was about surviving a decade of history sitting in an abandoned database, while a 30M+ events/day system kept running and the rest of the team kept shipping. Almost every “simple” idea fell apart once we accounted for downtime limits, consistency, and human error. What worked was a combination of boring, reliable pieces: a Data API in front of the databases, a purpose-built Go migrator with locks and checkpoints, small bounded windows, and a process designed so that failure just meant “retry later,” not “panic at midnight.”
We’re still migrating. But months in, the tool has held up, the team keeps shipping without noticing, and we haven’t had a data incident. For a years-overdue migration running in the background of a live system, that’s good enough.